Why Complex Entities Matter in a Fraud Rules Engine¶
Fraud systems rarely evaluate one flat record with a handful of fields.
Real transaction monitoring usually involves related entities:
- the
customer - the
sender - the
device - the
merchant - the
beneficiary - the payment instrument
Those entities often have their own attributes and sub-attributes:
customer.profile.agecustomer.behavior.avg_amount_30dsender.origin.countrysender.device.trust_score
If a fraud rules engine forces all of that into one flat namespace, the rule layer becomes harder to read, harder to maintain, and easier to break.
ezrules now supports canonical dotted nested paths in rule logic, test payloads, observations, backtesting, and the Tested Events UI. That makes it possible to model transactions as collections of related fraud entities instead of flattening everything into one long list of loosely related keys.
The practical problem with flat fraud payloads¶
Flattening looks simple at first:
{
"customer_country": "US",
"sender_country": "BR",
"sender_device_trust_score": 18,
"customer_profile_age": 34
}
But as a fraud program grows, flat naming starts to work against you:
- field names get long and inconsistent
- two teams may flatten the same concept differently
- related attributes lose their grouping
- the payload stops looking like the real business object it represents
- rule authors have to remember naming conventions instead of business meaning
That matters because fraud rules are not just technical filters. They are operational policy.
If an analyst reads a rule, they should be able to see the entity model immediately.
What complex entities look like in fraud monitoring¶
A more natural event model keeps related attributes together:
{
"amount": 875.5,
"currency": "USD",
"customer": {
"id": "cust_00042",
"country": "US",
"profile": {
"age": 34,
"segment": "established"
},
"behavior": {
"avg_amount_30d": 140.0,
"std_amount_30d": 30.0
}
},
"sender": {
"id": "cust_00042",
"country": "US",
"origin": {
"country": "BR"
},
"device": {
"trust_score": 18,
"age_days": 1
}
}
}
That structure mirrors how fraud teams actually think about an event:
- who is transacting
- from where
- on what device
- against what baseline
Rules become easier to read because the entity model is visible in the syntax itself.
Why this is useful in rule authoring¶
With nested-path support, an ezrules author can now write:
if $customer.profile.age >= 21 and $sender.device.trust_score <= 35 and $sender.origin.country != $customer.country:
return !HOLD
That is easier to reason about than a flat equivalent such as:
if $customer_profile_age >= 21 and $sender_device_trust_score <= 35 and $sender_origin_country != $customer_country:
return !HOLD
The dotted version communicates:
- which fields belong to the customer entity
- which fields belong to the sender entity
- which nested attributes are part of profile, behavior, origin, or device
In fraud detection work, this matters because many rules are about relationships across entities, not just thresholds on isolated fields.
Common fraud use cases for nested entities¶
Nested entity modeling is especially useful for:
Cross-entity mismatch checks¶
This is clearer than comparing two flattened country fields with ambiguous prefixes.
Device risk inside a sender context¶
The device is explicitly part of the sender entity rather than a standalone global field.
Customer baseline logic¶
if $customer.behavior.std_amount_30d > 0:
zscore = ($amount - $customer.behavior.avg_amount_30d) / $customer.behavior.std_amount_30d
if zscore >= 3:
return !HOLD
This keeps behavioral baselines grouped under the customer rather than spread across unrelated top-level names.
Mixed entity and top-level features¶
if $txn_type == "card_purchase" and $customer.profile.segment == "new" and $sender.device.age_days <= 1:
return !HOLD
That kind of rule is common in transaction monitoring: some signals are transaction-level, some are customer-level, and some belong to the sender or device context.
Why this helps operational teams, not just engineers¶
Nested entities are not only a schema preference. They improve day-to-day fraud operations.
1. Rules read more like policy¶
Analysts and fraud managers often review rule logic directly. Dotted paths make it easier to see what a rule is actually saying.
2. Event schemas stay closer to source systems¶
Many payment and case-management systems already expose nested objects. Preserving that shape avoids translation layers that create drift between the source event and the rule event.
3. It reduces naming collisions¶
Fields such as country, id, or age are common across entities. Nested paths make the scope explicit.
4. It improves investigation workflows¶
When an event is stored and reviewed later, the entity grouping still exists. That makes it easier to inspect what happened and why a rule fired.
What ezrules now supports around nested paths¶
This is not just parser-level syntax support. ezrules now handles canonical dotted paths across the full rule workflow:
- rule logic can reference nested fields such as
$customer.profile.age - missing nested fields produce path-aware errors
- field observations record canonical dotted paths
- field type configuration can target dotted paths
- the Test Rule panel pre-fills nested JSON objects for nested params
- backtesting applies the same nested-path normalization and eligibility logic
- the Tested Events page highlights nested referenced fields inside the JSON payload
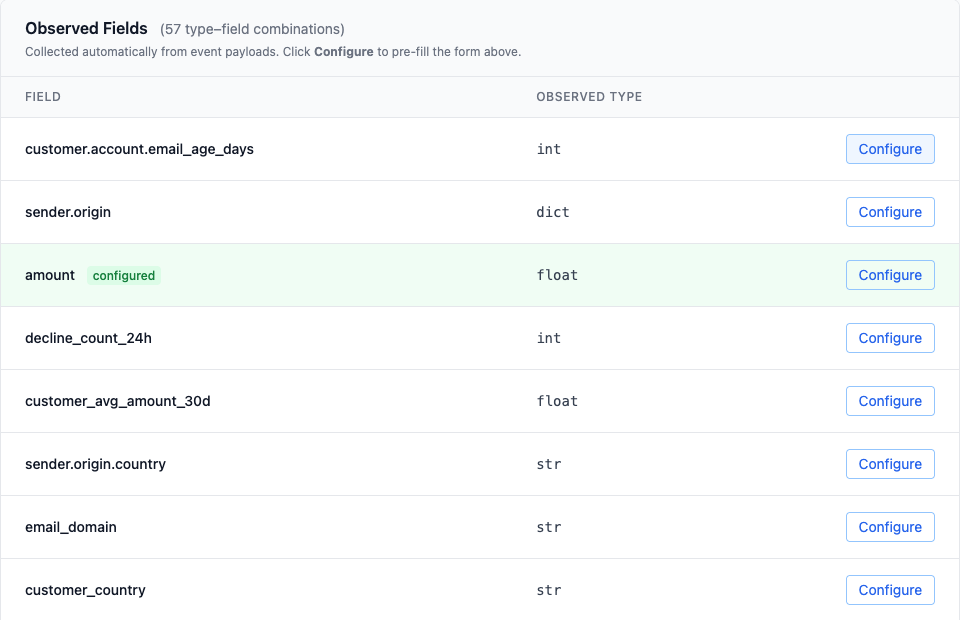
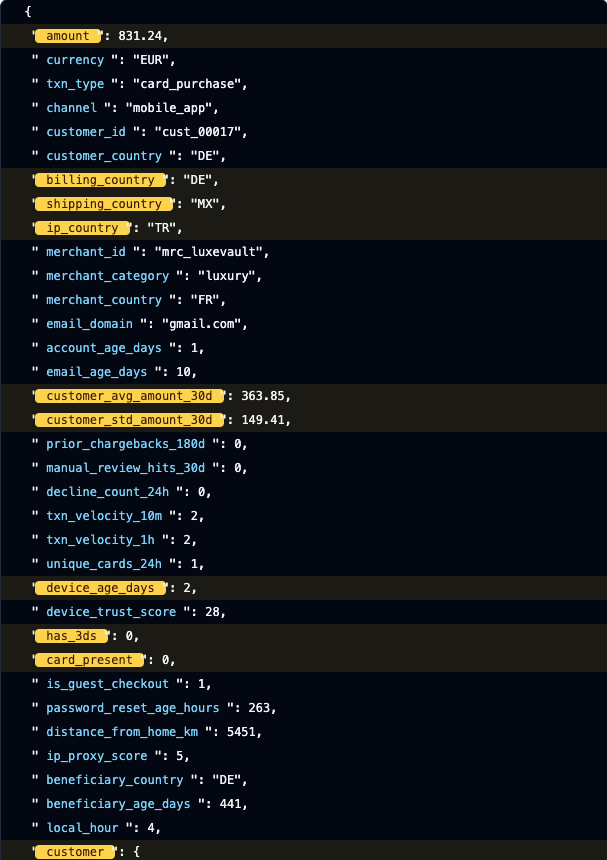
That end-to-end consistency matters. It is not enough to let authors type nested paths if every downstream tool still assumes flat fields.
Why this matters for fraud detection quality¶
Fraud rules often degrade when the event model is too lossy.
A flat payload tends to encourage:
- duplicated concepts
- weaker naming discipline
- rules that reference the wrong field because two similar fields look interchangeable
A more structured entity model makes it easier to write rules against the right concept and to explain why a rule fired.
That can reduce false positives caused by ambiguous field mapping, especially when several related countries, ids, or behavioral features exist in one event.
A useful middle ground¶
This does not mean every fraud event needs to become a deeply nested document.
A useful middle ground is:
- keep core transaction attributes at the top level when they truly are event-wide
- group entity-specific attributes under the entity they belong to
- use nested paths where the grouping carries operational meaning
For example:
- top-level:
amount,currency,txn_type - nested:
customer.profile.*,customer.behavior.*,sender.origin.*,sender.device.*
That gives rule authors the clarity of a structured model without making every rule overly verbose.
Final point¶
Fraud rules engines are not just evaluating values. They are evaluating relationships between entities.
As soon as the rule set starts asking questions like:
- "Is the sender origin different from the customer country?"
- "Is this device low-trust for this sender?"
- "Is the amount abnormal for this customer's baseline?"
you are already reasoning about complex entities.
At that point, the event model should help you, not hide the structure.
Nested-path support in ezrules is useful because it lets the fraud event look more like the fraud problem.
Related docs: